
Les algorithmes de régression font partie de la famille des algorithmes d’apprentissage automatique supervisé qui est un sous-ensemble des algorithmes d’apprentissage automatique. L’une des principales caractéristiques des algorithmes d’apprentissage supervisé est qu’ils modélisent les dépendances et les relations entre la sortie cible et les caractéristiques d’entrée afin de prédire la valeur pour les nouvelles données. Les algorithmes de régression prédisent les valeurs de sortie en fonction des caractéristiques d’entrée des données introduites dans le système. La méthodologie de go-to est l’algorithme construit un modèle sur les caractéristiques des données de formation et en utilisant le modèle pour prédire la valeur pour les nouvelles données.
Selon Oracle, voici une excellente définition de la régression – une fonction d’exploration de données pour prédire un nombre. Exemple concret, comment les modèles de régression sont exploités pour prédire la valeur des biens immobiliers en fonction de l’emplacement, de la taille et d’autres facteurs. Aujourd’hui, les modèles de régression ont de nombreuses applications, notamment dans les prévisions financières, l’analyse des tendances, le marketing, la prédiction des séries chronologiques et même la modélisation de la réponse aux médicaments. Certains des types populaires d’algorithmes de régression sont la régression linéaire, les arbres de régression, la régression lasso et la régression multivariée.

Analytics India Magazine dresse la liste des algorithmes de régression les plus populaires
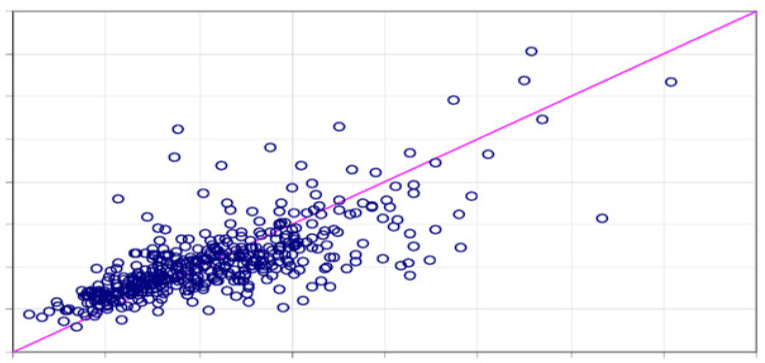

1. Modèle de régression linéaire simple : La régression linéaire simple est une méthode statistique qui permet aux utilisateurs de résumer et d’étudier les relations entre deux variables continues (quantitatives). La régression linéaire est un modèle linéaire dans lequel un modèle qui suppose une relation linéaire entre les variables d’entrée (x) et la variable de sortie unique (y). Ici, la variable y peut être calculée à partir d’une combinaison linéaire des variables d’entrée (x). Lorsqu’il y a une seule variable d’entrée (x), la méthode est appelée régression linéaire simple. Lorsqu’il y a plusieurs variables d’entrée, la procédure est appelée régression linéaire multiple.
Application : certaines des applications les plus populaires de l’algorithme de régression linéaire sont dans la prédiction des portefeuilles financiers, la prévision des salaires, les prédictions immobilières et dans le trafic pour arriver aux ETA.
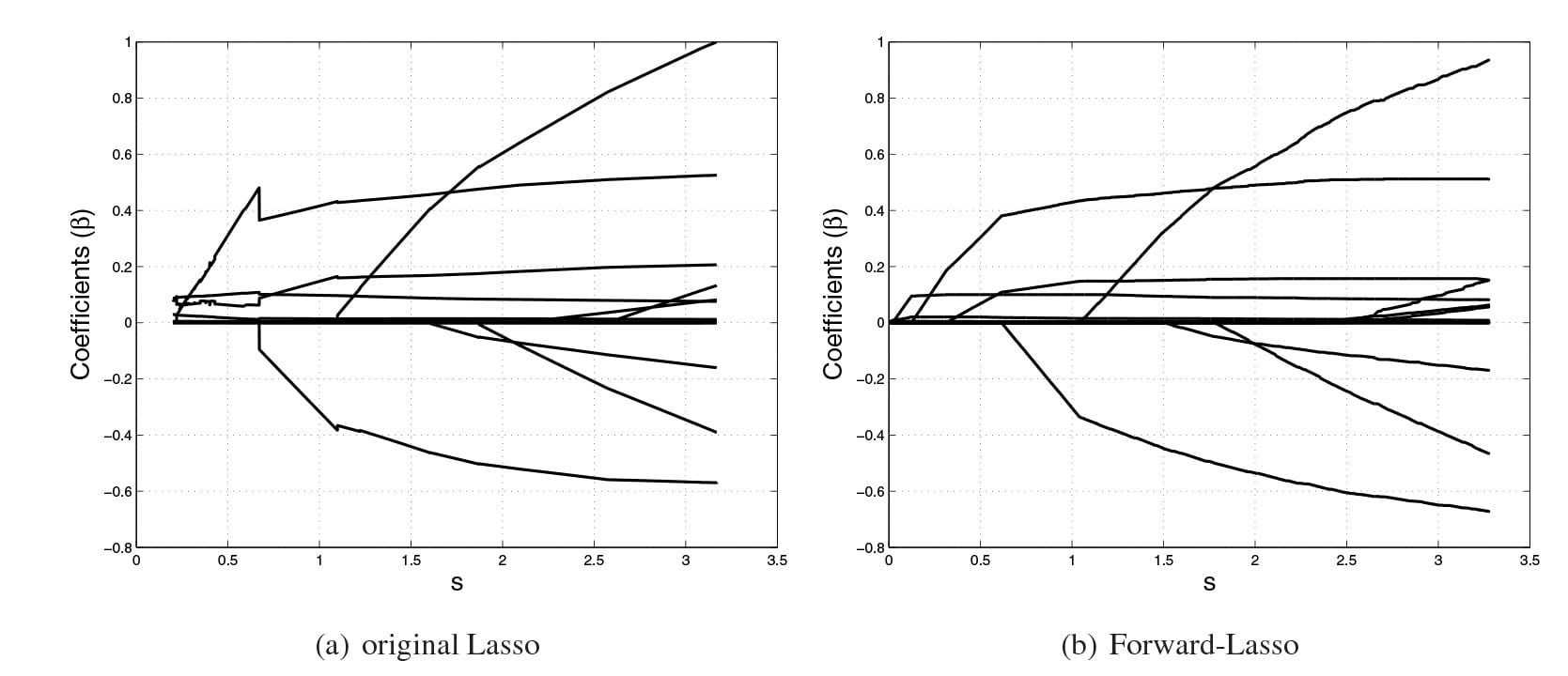
2. Régression Lasso : LASSO signifie Least Absolute Selection Shrinkage Operator dans lequel le rétrécissement est défini comme une contrainte sur les paramètres. L’objectif de la régression lasso est d’obtenir le sous-ensemble de prédicteurs qui minimise l’erreur de prédiction pour une variable de réponse quantitative. L’algorithme fonctionne en imposant une contrainte sur les paramètres du modèle qui entraîne un rétrécissement des coefficients de régression de certaines variables vers un zéro.
Les variables dont le coefficient de régression est égal à zéro après le processus de rétrécissement sont exclues du modèle. Les variables dont les coefficients de régression sont non nuls sont les plus fortement associées à la variable réponse. Les variables explicatives peuvent être soit quantitatives, soit catégorielles, soit les deux. Cette analyse de régression lasso est essentiellement une méthode de rétrécissement et de sélection des variables et elle aide les analystes à déterminer quels sont les prédicteurs les plus importants.
Application : Les algorithmes de régression lasso ont été largement utilisés dans les réseaux financiers et l’économie. En finance, son application est vue dans la prévision des probabilités de défaut et les modèles de prévision basés sur Lasso sont utilisés pour évaluer le cadre de risque à l’échelle de l’entreprise. Les régressions de type Lasso sont également utilisées pour effectuer des plates-formes de test de stress pour analyser plusieurs scénarios de stress.
3. régression logistique : L’une des techniques de régression les plus couramment utilisées dans l’industrie qui sont largement appliquées à travers la détection de la fraude, le scoring des cartes de crédit et les essais cliniques, partout où la réponse est binaire a un avantage majeur. L’un des principaux avantages de cet algorithme populaire est que l’on peut inclure plus d’une variable dépendante qui peut être continue ou dichotomique. L’autre avantage majeur de cet algorithme d’apprentissage automatique supervisé est qu’il fournit une valeur quantifiée pour mesurer la force de l’association en fonction du reste des variables. Malgré sa popularité, les chercheurs ont tiré ses limites, citant un manque de technique robuste et aussi une grande dépendance du modèle.
Application : Aujourd’hui, les entreprises déploient la régression logistique pour prédire la valeur des maisons dans les affaires immobilières, la valeur de la durée de vie des clients dans le secteur de l’assurance et sont exploitées pour produire un résultat continu tel que le fait de savoir si un client peut acheter / achètera le scénario.
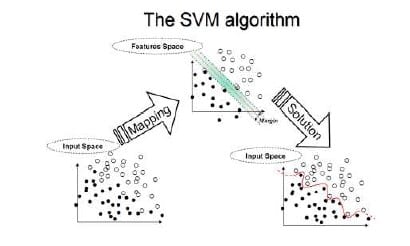
4. Machines à vecteurs de support : Support Vector Machine (SVM) est un autre algorithme le plus puissant avec des bases théoriques solides basées sur la théorie de Vapnik-Chervonenkis, comme défini par les docs d’Oracle. Cet algorithme d’apprentissage automatique supervisé dispose d’une forte régularisation et peut être utilisé à la fois pour la classification et la régression. Ils sont caractérisés par l’utilisation de noyaux, la rareté de la solution et le contrôle de la capacité obtenu en agissant sur la marge, ou sur le nombre de vecteurs de support, etc. La capacité du système est contrôlée par des paramètres qui ne dépendent pas de la dimension de l’espace des caractéristiques. Comme l’algorithme SVM opère nativement sur des attributs numériques, il utilise une normalisation de type z-score sur les attributs numériques. En régression, les algorithmes de Machines à Vecteur de Support utilisent la fonction de perte epsilon-insensibilité (marge de tolérance) pour résoudre les problèmes de régression.

Application : les algorithmes de régression des machines à vecteurs de support ont trouvé plusieurs applications dans l’industrie pétrolière et gazière, la classification d’images et de textes et la catégorisation d’hypertextes. Dans les champs pétroliers, il est spécifiquement exploité pour l’exploration afin de comprendre la position des couches de roches et de créer des modèles 2D et 3D comme représentation du sous-sol.
5. Algorithme de régression multivariée : Cette technique est utilisée lorsqu’il y a plus d’une variable prédictive dans un modèle de régression multivariée et le modèle est appelé régression multiple multivariée. Considéré par les chercheurs comme l’un des algorithmes d’apprentissage automatique supervisé les plus simples, cet algorithme de régression est utilisé pour prédire la variable de réponse pour un ensemble de variables explicatives. Cette technique de régression peut être mise en œuvre efficacement à l’aide d’opérations matricielles et en Python, elle peut être mise en œuvre via la bibliothèque « numpy » qui contient des définitions et des opérations pour l’objet matrice.
Application : L’application industrielle de l’algorithme de régression multivariée est vue fortement dans le secteur du commerce de détail où les clients font un choix sur un certain nombre de variables telles que la marque, le prix et le produit. L’analyse multivariée aide les décideurs à trouver la meilleure combinaison de facteurs pour augmenter la fréquentation du magasin.
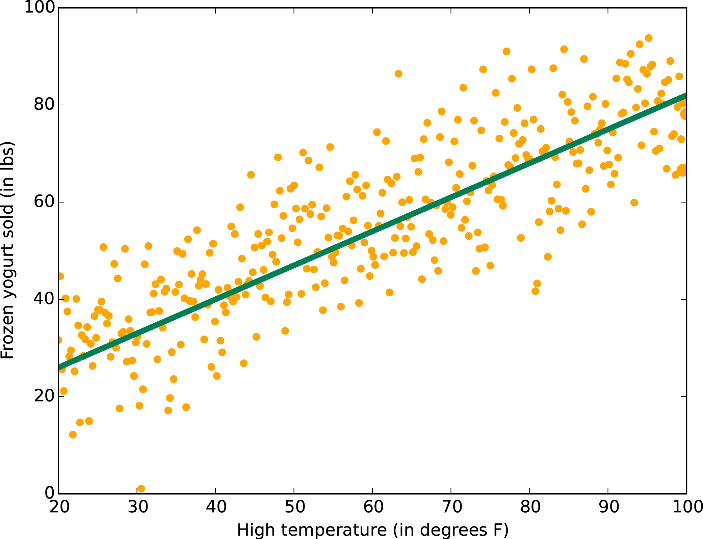
6. Algorithme de régression multiple : Cet algorithme de régression a plusieurs applications à travers l’industrie pour la tarification des produits, la tarification immobilière, les départements marketing pour connaître l’impact des campagnes. Contrairement à la technique de régression linéaire, la régression multiple, est une classe plus large de régressions qui englobe les régressions linéaires et non linéaires avec plusieurs variables explicatives.
Application : Certaines des applications commerciales de l’algorithme de régression multiple dans l’industrie sont dans la recherche en sciences sociales, l’analyse comportementale et même dans l’industrie de l’assurance pour déterminer la valeur des réclamations.
S’abonner à notre newsletter
Recevoir les dernières mises à jour et des offres pertinentes en partageant votre email.
0 commentaire