
Algoritmos de Regressão enquadram-se na família de algoritmos de Aprendizagem de Máquinas Supervisionados, que é um subconjunto de algoritmos de aprendizagem de máquinas. Uma das principais características dos algoritmos de aprendizagem supervisionada é que eles modelam dependências e relações entre as características de saída e entrada do alvo para prever o valor de novos dados. Os algoritmos de regressão prevêem os valores de saída com base nas características de entrada dos dados alimentados no sistema. A metodologia go-to é o algoritmo constrói um modelo sobre as características dos dados de treino e utilizando o modelo para prever o valor para novos dados.
De acordo com Oracle, aqui está uma grande definição de Regressão – uma função de mineração de dados para prever um número. Caso em questão, como os modelos de regressão são alavancados para prever o valor imobiliário com base na localização, tamanho e outros factores. Actualmente, os modelos de regressão têm muitas aplicações, particularmente em previsão financeira, análise de tendências, marketing, previsão de séries cronológicas e mesmo modelação de resposta a drogas. Alguns dos tipos populares de algoritmos de regressão são a regressão linear, árvores de regressão, regressão laço e regressão multivariada.

Analytics India Magazine lista os algoritmos de regressão mais populares
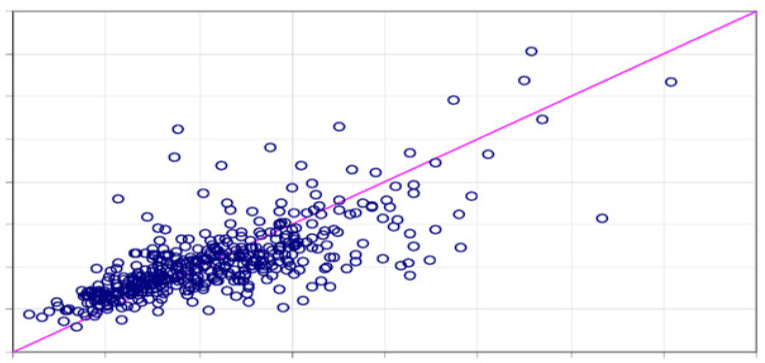

1. Modelo de Regressão Linear Simples: A regressão linear simples é um método estatístico que permite aos utilizadores resumir e estudar as relações entre duas variáveis contínuas (quantitativas). A regressão linear é um modelo linear em que um modelo assume uma relação linear entre as variáveis de entrada (x) e a variável de saída única (y). Aqui, o y pode ser calculado a partir de uma combinação linear das variáveis de entrada (x). Quando existe uma única variável de entrada (x), o método é chamado de regressão linear simples. Quando há múltiplas variáveis de entrada, o procedimento é referido como regressão linear múltipla.
Aplicação: algumas das aplicações mais populares do algoritmo de regressão linear estão na previsão de carteira financeira, previsão de salários, previsões imobiliárias e no tráfego ao chegar a ETAs.
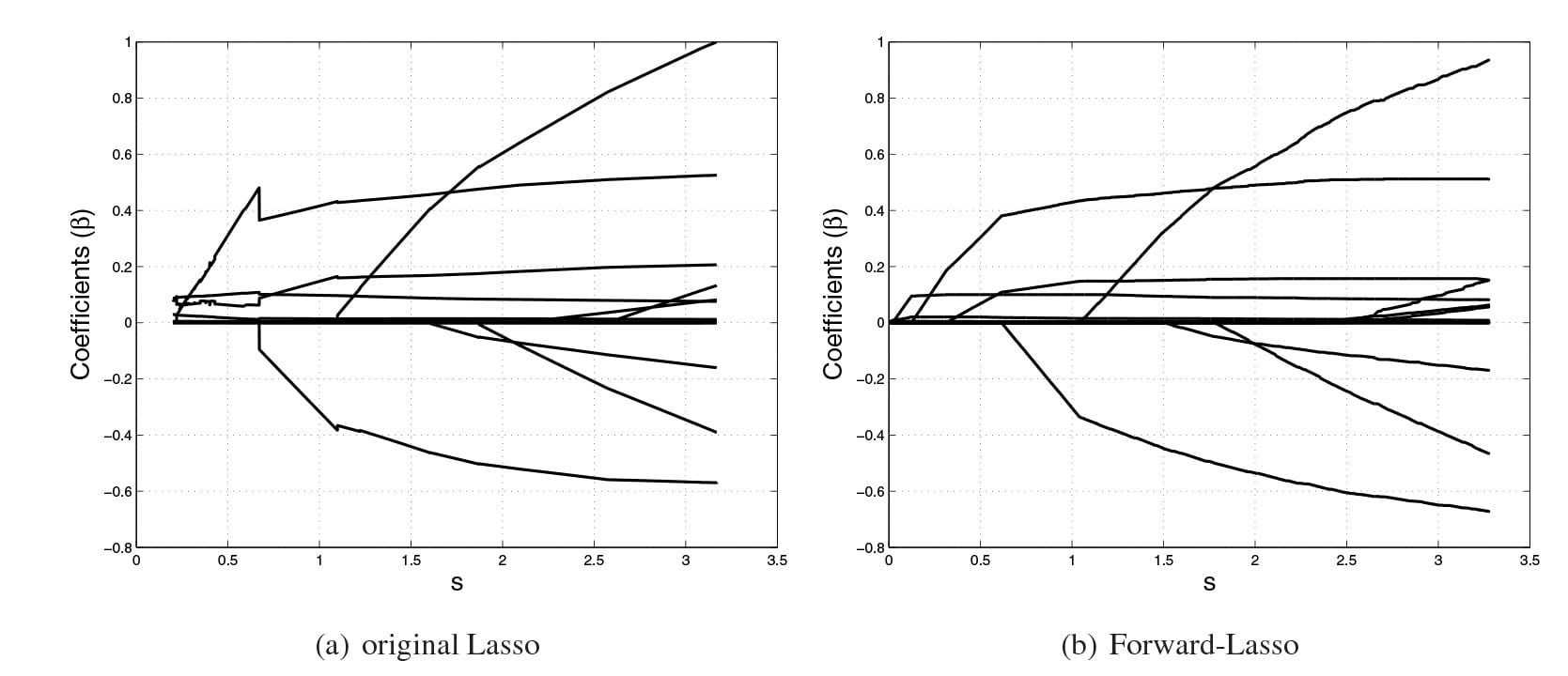
2. Regressão Lasso: LASSO significa “Minimum Absolute Selection Shrinkage Operator” (Operador de Retracção Menos Absoluta), em que a retracção é definida como uma restrição aos parâmetros. O objectivo da regressão Lasso é obter o subconjunto de preditores que minimizam o erro de previsão para uma variável de resposta quantitativa. O algoritmo funciona impondo uma restrição aos parâmetros do modelo que faz com que os coeficientes de regressão de algumas variáveis encolham para um zero.
Variáveis com um coeficiente de regressão igual a zero após o processo de retracção são excluídas do modelo. As variáveis com coeficientes de regressão não nulos são as mais fortemente associadas à variável de resposta. As variáveis explicativas podem ser quantitativas, categóricas ou ambas. Esta última análise de regressão é basicamente um método de retracção e selecção de variáveis e ajuda os analistas a determinar quais dos preditores são mais importantes.
Aplicação: Os algoritmos de regressão Lasso têm sido amplamente utilizados em redes financeiras e economia. Nas finanças, a sua aplicação é vista nas probabilidades de previsão de incumprimento e os modelos de previsão baseados no Lasso são utilizados na avaliação do quadro de risco das empresas. As regressões do tipo Lasso são também utilizadas para realizar plataformas de teste de esforço para analisar múltiplos cenários de esforço.
3. regressão logística: Uma das técnicas de regressão mais comummente utilizadas na indústria que são amplamente aplicadas na detecção de fraudes, pontuação de cartões de crédito e ensaios clínicos, sempre que a resposta é binária, tem uma grande vantagem. Uma das principais vantagens deste popular algoritmo é que se pode incluir mais de uma variável dependente que pode ser contínua ou dicotómica. A outra grande vantagem deste algoritmo de aprendizagem supervisionada da máquina é que fornece um valor quantificado para medir a força de associação de acordo com o resto das variáveis. Apesar da sua popularidade, os investigadores têm vindo a delinear as suas limitações, citando uma falta de técnica robusta e também uma grande dependência do modelo.
Aplicação: Hoje em dia, as empresas implementam a Regressão Logística para prever os valores da casa no negócio imobiliário, o valor vitalício do cliente no sector dos seguros e são alavancadas para produzir um resultado contínuo, tal como se um cliente pode comprar/venderá um cenário.
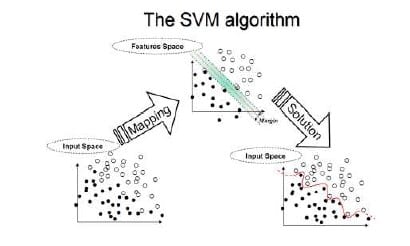
4. Máquinas Vectoriais de Apoio: Support Vector Machine (SVM) é outro algoritmo mais poderoso com fortes fundamentos teóricos baseados na teoria Vapnik-Chervonenkis, tal como definido pelos documentos Oracle. Este algoritmo supervisionado de aprendizagem de máquinas tem forte regularização e pode ser alavancado tanto para desafios de classificação como de regressão. Caracterizam-se pela utilização de kernels, a escassez da solução e o controlo da capacidade obtida actuando sobre a margem, ou sobre o número de vectores de suporte, etc. A capacidade do sistema é controlada por parâmetros que não dependem da dimensionalidade do espaço de características. Uma vez que o algoritmo SVM funciona nativamente em atributos numéricos, utiliza uma normalização de z-score em atributos numéricos. Na regressão, os algoritmos Support Vector Machines utilizam a função de perda de sensibilidade (margem de tolerância) epsilon para resolver problemas de regressão.

Aplicação: os algoritmos de regressão de máquinas vectoriais de suporte têm encontrado várias aplicações na indústria petrolífera e de gás, classificação de imagens e categorização de texto e hipertexto. Nos campos petrolíferos, é especificamente aproveitado para a exploração para compreender a posição das camadas de rochas e criar modelos 2D e 3D como representação do subsolo.
5. Algoritmo de Regressão Multivariada: Esta técnica é utilizada quando existe mais do que uma variável preditor num modelo de regressão multivariada e o modelo é chamado de regressão múltipla multivariada. Denominado pelos investigadores como um dos mais simples algoritmos de aprendizagem supervisionada da máquina, este algoritmo de regressão é utilizado para prever a variável de resposta para um conjunto de variáveis explicativas. Esta técnica de regressão pode ser implementada eficazmente com a ajuda de operações matriciais e, em Python, pode ser implementada através da biblioteca “numpy” que contém definições e operações para o objecto matriz.
Aplicação: A aplicação do algoritmo de Regressão Multivariada na indústria é vista em grande medida no sector retalhista, onde os clientes fazem uma escolha sobre uma série de variáveis tais como marca, preço e produto. A análise multivariada ajuda os decisores a encontrar a melhor combinação de factores para aumentar as quedas dos pés na loja.
6. Algoritmo de Regressão Múltipla: Este algoritmo de regressão tem várias aplicações em toda a indústria para o preço de produtos, preços imobiliários, departamentos de marketing para descobrir o impacto das campanhas. Ao contrário da técnica de regressão linear, a regressão múltipla, é uma classe mais ampla de regressões que engloba regressões lineares e não lineares com múltiplas variáveis explicativas.
Aplicação: Algumas das aplicações empresariais do algoritmo de regressão múltipla na indústria são na investigação das ciências sociais, análise comportamental e mesmo na indústria dos seguros para determinar a solvabilidade dos sinistros.
Subscreva a nossa Newsletter
Obtenha as últimas actualizações e ofertas relevantes, partilhando o seu e-mail.
0 comentários