
Independentemente da sua posição sobre a questão da Sexualidade da Ciência dos Dados, é simplesmente impossível ignorar a importância contínua dos dados, e a nossa capacidade de os analisar, organizar, e contextualizar. Com base nas suas vastas reservas de dados de emprego e no feedback dos empregados, Glassdoor classificou o Data Scientist #1 na sua lista dos 25 Melhores Empregos na América. Assim, o papel está aqui para ficar, mas inquestionavelmente, as especificidades do que um Data Scientist faz irá evoluir. Com tecnologias como o Machine Learning a tornar-se cada vez mais comum, e campos emergentes como o Deep Learning a ganharem uma tracção significativa entre investigadores e engenheiros – e as empresas que os contratam – os Data Scientists continuam a cavalgar a crista de uma incrível onda de inovação e progresso tecnológico.
Embora tenha uma forte capacidade de codificação seja importante, a ciência de dados não se resume à engenharia de software (de facto, tenha uma boa familiaridade com Python e está pronto para ir). Os cientistas de dados vivem na intersecção da codificação, da estatística e do pensamento crítico. Como Josh Wills disse, “o cientista de dados é uma pessoa que é melhor em estatística do que qualquer programador e melhor em programação do que qualquer estatístico”. Conheço pessoalmente demasiados engenheiros de software que procuram fazer a transição para cientista de dados e utilizam cegamente estruturas de aprendizagem de máquinas tais como TensorFlow ou Apache Spark para os seus dados sem uma compreensão completa das teorias estatísticas por detrás deles. Assim vem o estudo da aprendizagem estatística, uma estrutura teórica para o desenho da aprendizagem de máquinas a partir dos campos da estatística e da análise funcional.
Porquê estudar a Aprendizagem Estatística? É importante compreender as ideias subjacentes às várias técnicas, a fim de saber como e quando utilizá-las. É preciso compreender primeiro os métodos mais simples, a fim de apreender os mais sofisticados. É importante avaliar com precisão o desempenho de um método, para saber até que ponto está a funcionar bem ou mal. Além disso, esta é uma área de investigação estimulante, tendo aplicações importantes na ciência, na indústria e nas finanças. Em última análise, a aprendizagem estatística é um ingrediente fundamental na formação de um moderno cientista de dados. Exemplos de problemas de aprendizagem estatística incluem:
- Identificar os factores de risco de cancro da próstata.
- Classificar um fonema registado com base num log-periodograma.
- Prever se alguém terá um ataque cardíaco com base em medições demográficas, dietéticas e clínicas.
- Personalizar um sistema de detecção de spam por correio electrónico.
- Identificar os números num código postal manuscrito.
- Classificar uma amostra de tecido numa de várias classes de cancro.
- Estabelecer a relação entre o salário e as variáveis demográficas nos dados dos inquéritos à população.
No meu último semestre na faculdade, fiz um Estudo Independente sobre Data Mining. A aula cobre materiais expansivos provenientes de 3 livros: Introdução à Aprendizagem Estatística (Hastie, Tibshirani, Witten, James), Doing Bayesian Data Analysis (Kruschke), e Time Series Analysis and Applications (Shumway, Stoffer). Fizemos muitos exercícios sobre Análise Bayesiana, Markov Chain Monte Carlo, Modelação Hierárquica, Aprendizagem supervisionada e não supervisionada. Esta experiência aprofunda o meu interesse no campo académico de Data Mining e convence-me a especializar-me ainda mais neste campo. Recentemente, completei o curso online Statistical Learning sobre Stanford Lagunita, que cobre todo o material do livro Intro to Statistical Learning que li no meu Estudo Independente. Agora, sendo exposto ao conteúdo duas vezes, quero partilhar as 10 técnicas estatísticas do livro que acredito que quaisquer cientistas de dados deveriam aprender a ser mais eficazes no tratamento de grandes conjuntos de dados.
Antes de avançar com estas 10 técnicas, quero diferenciar entre aprendizagem estatística e aprendizagem mecânica. Escrevi anteriormente um dos mais populares posts de Média sobre aprendizagem de máquinas, por isso estou confiante que tenho a perícia necessária para justificar estas diferenças:
- Aprendizagem de máquinas surgiu como um subcampo de Inteligência Artificial.
- Aprendizagem estatística surgiu como um subcampo de Estatística.
- Aprendizagem de máquinas tem uma maior ênfase em aplicações de grande escala e precisão de previsão.
- Aprendizagem estatística enfatiza modelos e a sua interpretabilidade, e precisão e incerteza.
- Mas a distinção tornou-se e mais desfocada, e há uma grande quantidade de “fertilização cruzada”.”
- Aprendizagem da máquina tem a vantagem no Marketing!
1 – Regressão Linear:
Na estatística, a regressão linear é um método para prever uma variável alvo, encaixando a melhor relação linear entre a variável dependente e a independente. O melhor ajuste é feito certificando-se de que a soma de todas as distâncias entre a forma e as observações reais em cada ponto é tão pequena quanto possível. O ajuste da forma é “melhor” no sentido de que nenhuma outra posição produziria menos erros, dada a escolha da forma. 2 tipos principais de regressão linear são a Regressão Linear Simples e a Regressão Linear Múltipla. A Regressão Linear Simples utiliza uma única variável independente para prever uma variável dependente através do encaixe de uma melhor relação linear. A Regressão Linear Múltipla utiliza mais do que uma variável independente para prever uma variável dependente encaixando uma melhor relação linear.
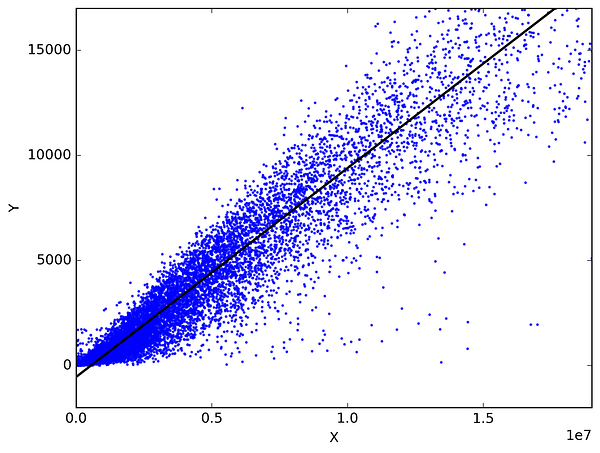
Escolha quaisquer 2 coisas que utilize na sua vida diária e que estejam relacionadas. Como, tenho dados das minhas despesas mensais, rendimentos mensais e o número de viagens por mês durante os últimos 3 anos. Agora preciso de responder às seguintes perguntas:
- Quais serão as minhas despesas mensais para o próximo ano?
- Qual o factor (rendimento mensal ou número de viagens por mês) que é mais importante para decidir as minhas despesas mensais?
- Como o rendimento mensal e as viagens por mês estão correlacionados com as despesas mensais?
2 – Classificação:
Classificação é uma técnica de prospecção de dados que atribui categorias a uma recolha de dados de modo a ajudar em previsões e análises mais precisas. Também por vezes denominada Árvore de Decisão, a classificação é um dos vários métodos destinados a tornar eficaz a análise de conjuntos de dados muito grandes. Destacam-se 2 grandes técnicas de Classificação: Regressão Logística e Análise Discriminatória.
Regressão Logística é a análise de regressão apropriada para conduzir quando a variável dependente é dicotómica (binária). Como todas as análises de regressão, a regressão logística é uma análise preditiva. A regressão logística é utilizada para descrever dados e para explicar a relação entre uma variável binária dependente e uma ou mais variáveis nominais, ordinais, de intervalo ou independentes de nível de raciocínio. Tipos de questões que uma regressão logística pode examinar:
- Como é que a probabilidade de contrair cancro do pulmão (Sim vs Não) muda por cada quilo adicional de excesso de peso e por cada maço de cigarros fumado por dia?
- O consumo de calorias de peso corporal, ingestão de gordura e idade dos participantes tem influência nos ataques cardíacos (Sim vs Não)?
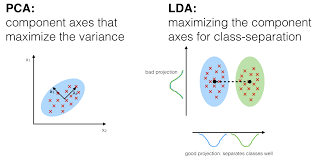
Na Análise Discriminatória, 2 ou mais grupos ou grupos ou populações são conhecidos a priori e 1 ou mais novas observações são classificadas em 1 das populações conhecidas com base nas características medidas. A Análise Discriminatória modela a distribuição dos preditores X separadamente em cada uma das classes de resposta, e depois utiliza o teorema de Bayes para inverter estes em estimativas da probabilidade da categoria de resposta dado o valor de X. Tais modelos podem ser lineares ou quadráticos.
- Linear Discriminant Analysis calcula “pontuações discriminantes” para cada observação para classificar em que classe de variável de resposta se encontra. Estas pontuações são obtidas ao encontrar combinações lineares das variáveis independentes. Assume que as observações dentro de cada classe são extraídas de uma distribuição gaussiana multivariada e a covariância das variáveis preditoras é comum em todos os k níveis da variável de resposta Y.
- Análise Discriminatória Quadrática fornece uma abordagem alternativa. Tal como a LDA, QDA assume que as observações de cada classe de Y são extraídas de uma distribuição gaussiana. Contudo, ao contrário do LDA, QDA assume que cada classe tem a sua própria matriz de covariância. Por outras palavras, não se assume que as variáveis preditoras tenham variância comum em cada um dos níveis de k em Y.
3 – Métodos de Amostragem:
Amostragem é o método que consiste em desenhar amostras repetidas a partir das amostras de dados originais. Trata-se de um método não paramétrico de inferência estatística. Por outras palavras, o método de re-amostragem não envolve a utilização das tabelas de distribuição genéricas para calcular valores aproximados de probabilidade p.
Reamostragem gera uma distribuição de amostras única com base nos dados reais. Utiliza métodos experimentais, em vez de métodos analíticos, para gerar a distribuição única de amostragem. Produz estimativas imparciais uma vez que se baseia nas amostras imparciais de todos os resultados possíveis dos dados estudados pelo investigador. Para compreender o conceito de reamostragem, deve compreender os termos Bootstrapping e Cross-Validation:
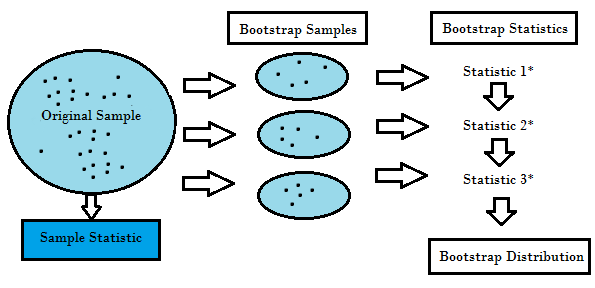
- Bootstrapping é uma técnica que ajuda em muitas situações como a validação de um desempenho preditivo do modelo, métodos de conjunto, estimativa de enviesamento e variância do modelo. Funciona por amostragem com substituição dos dados originais, e toma os pontos de dados “não escolhidos” como casos de teste. Podemos fazer isto várias vezes e calcular a pontuação média como estimativa do desempenho do nosso modelo.
- Por outro lado, a validação cruzada é uma técnica para validar o desempenho do modelo, e é feita através da divisão dos dados de treino em k partes. Tomamos as k – 1 partes como o nosso conjunto de treino e utilizamos a parte “realizada” como o nosso conjunto de teste. Repetimos isso k vezes de forma diferente. Finalmente, tomamos a média das notas k como a nossa estimativa de desempenho.
Usualmente para modelos lineares, os mínimos quadrados comuns são os critérios principais a serem considerados para os encaixar nos dados. Os 3 métodos seguintes são as abordagens alternativas que podem fornecer melhor precisão de previsão e interpretabilidade do modelo para a inserção de modelos lineares.
4 – Selecção de subconjuntos:
Esta abordagem identifica um subconjunto dos preditores p que acreditamos estar relacionado com a resposta. Depois encaixamos um modelo utilizando os mínimos quadrados das características do subconjunto.
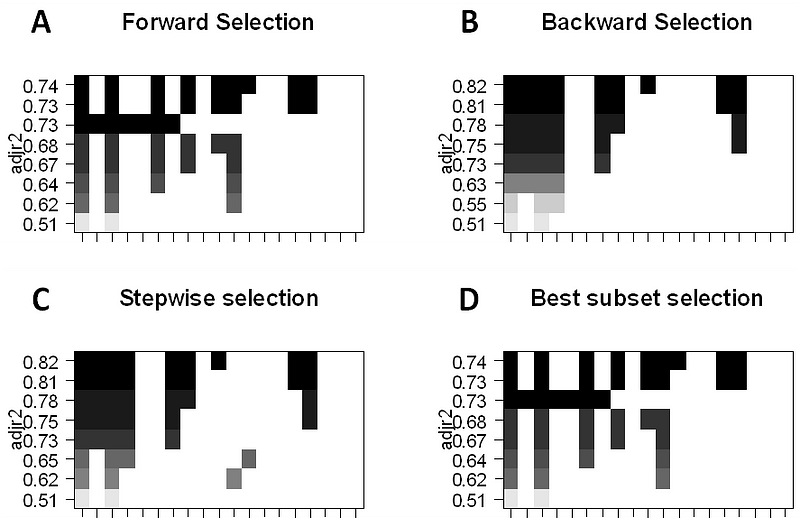
- Selecção do melhor subconjunto: Aqui encaixamos uma regressão OLS separada para cada combinação possível dos preditores p e depois olhamos para o modelo resultante encaixa. O algoritmo é dividido em 2 fases: (1) Encaixa todos os modelos que contêm k preditores, onde k é o comprimento máximo dos modelos, (2) Selecciona um único modelo usando erro de previsão validado cruzado. É importante utilizar erro de teste ou de validação, e não erro de treino para avaliar o ajuste do modelo porque RSS e R² aumentam monotonicamente com mais variáveis. A melhor abordagem é validar e escolher o modelo com o maior R² e o menor RSS sobre estimativas de erro de teste.
- Selecção por etapas considera um subconjunto muito mais pequeno de prognósticos. Começa com um modelo sem preditores, depois adiciona preditores ao modelo, um de cada vez até que todos os preditores estejam no modelo. A ordem das variáveis a serem adicionadas é a variável, que dá a maior melhoria de adição ao ajuste, até que nenhuma outra variável melhore o ajuste do modelo usando erro de previsão validado cruzado.
- Backward Stepwise Selection começa com todos os p preditores do modelo, depois remove iterativamente o preditor menos útil, um de cada vez.
- Métodos Híbridos segue a abordagem gradual para a frente, contudo, após adicionar cada nova variável, o método pode também remover variáveis que não contribuem para o ajuste do modelo.
5 – Encolhimento:
Esta abordagem encaixa num modelo que envolve todos os preditores p, contudo, os coeficientes estimados são reduzidos a zero em relação às estimativas dos mínimos quadrados. Esta retracção, também conhecida como regularização, tem o efeito de reduzir a variância. Dependendo do tipo de encolhimento efectuado, alguns dos coeficientes podem ser estimados como sendo exactamente zero. Assim, este método efectua também a selecção de variáveis. As duas técnicas mais conhecidas para reduzir o coeficiente estimado para zero são a regressão da crista e o laço.
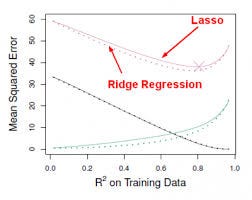
- A regressão da crista é semelhante aos mínimos quadrados, excepto que os coeficientes são estimados através da minimização de uma quantidade ligeiramente diferente. A regressão de cristas, tal como a OLS, procura estimativas de coeficientes que reduzem RSS, mas também têm uma penalização de retracção quando os coeficientes se aproximam de zero. Esta penalização tem o efeito de reduzir as estimativas dos coeficientes para zero. Sem entrar na matemática, é útil saber que a regressão de cristas encolhe as características com a menor variação do espaço da coluna. Tal como na análise de componentes prinicipais, a regressão de cristas projecta os dados para o espaço direccional e depois reduz os coeficientes dos componentes de baixa variância mais do que os componentes de alta variância, que são equivalentes aos componentes principais maiores e mais pequenos.
regressão de cristas tinha pelo menos uma desvantagem; inclui todos os preditores de p no modelo final. O termo de penalização irá colocar muitos deles perto de zero, mas nunca exactamente a zero. Isto não é geralmente um problema para a precisão da previsão, mas pode tornar o modelo mais difícil de interpretar os resultados. A Lasso supera esta desvantagem e é capaz de forçar a zero alguns dos coeficientes concedidos que s são suficientemente pequenos. Uma vez que s = 1 resulta em regressão regular de OLS, à medida que s se aproxima de 0, os coeficientes diminuem para zero. Assim, a regressão Lasso também realiza a selecção de variáveis.
0 comentários